Table of Contents
- Obtaining the Axiom Binary
- Creating an object model programmatically
- Creating an object model by parsing an XML document
- Namespaces
- Traversing
- Serializer
- Complete Code for the Axiom based Document Building and Serialization
- Creating stream readers and writers using
StAXUtils - Releasing the parser
- Exception handling
There are several methods through which the Axiom binary can be obtained:
If your project uses Maven, then it is sufficient to add Axiom as a dependency, as described in the section called “Using Axiom in a Maven 2 project”. Releases are available from the central repository, and snapshots are available from
http://repository.apache.org/snapshots/.A prebuilt binary distribution can be downloaded from the site. Source distributions are also available. They can be built using Maven 2, by executing mvn install in the root directory of the distribution.
It is also possible to check out the source code for the current development version (trunk) or previous releases from the Subversion repository and build it using Maven 2. Detailed information on getting the source code from the Subversion repository is found here.
Once the Axiom binary is obtained by any of the above ways, it should be
included in the classpath for any of the Axiom based programs to work.
Subsequent sections of this guide assume that this build step is complete
and axiom-api-2.0.0.jar and axiom-impl-2.0.0.jar are
present in the classpath along with the StAX API jar file and a StAX
implementation.
An object model instance can be created programmatically by instantiating the objects
representing the individual nodes of the document and then assembling them into a
tree structure. Axiom defines a set of interfaces representing the different node types.
E.g. OMElement represents an element, while OMText
represents character data that appears inside an element.
Axiom requires that all node instances are created using a factory.
The reason for this is to cater for different implementations of the Axiom API,
as shown in Figure 2.1, “The Axiom API with different implementations”.
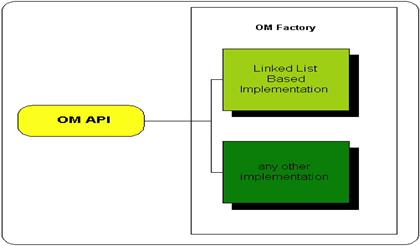
Two implementations are currently shipped with Axiom:
The Linked List implementation (LLOM). This is the standard implementation. As the name implies, it uses linked lists to store collections of nodes.
DOOM (DOM over OM), which adds support for the DOM API.
For each implementation, there are actually three factories: one for plain XML, and the other
ones for the two SOAP versions. The factories for the default implementation can be obtained
by calling the appropriate static methods in OMAbstractFactory.
E.g. OMAbstractFactory.getOMFactory() will return the proper
factory for plain XML. Example 2.1, “Creating an object model programmatically” shows how this factory is used to create
several OMElement instances.
Example 2.1. Creating an object model programmatically
//create a factory
OMFactory factory = OMAbstractFactory.getOMFactory();
//use the factory to create two namespace objects
OMNamespace ns1 = factory.createOMNamespace("bar","x");
OMNamespace ns2 = factory.createOMNamespace("bar1","y");
//use the factory to create three elements
OMElement root = factory.createOMElement("root",ns1);
OMElement elt11 = factory.createOMElement("foo1",ns1);
OMElement elt12 = factory.createOMElement("foo2",ns1);
The Axiom API defines several methods to assemble individual objects into a tree
structure. The most prominent ones are the following two methods available on
OMElement instances:
public void addChild(OMNode omNode); public void addAttribute(OMAttribute attr);
addChild will always add the child as the last child of the parent.
Example 2.2, “Usage of addChild” shows how this method is used to assemble the three elements
created in Example 2.1, “Creating an object model programmatically” into a tree structure.
Example 2.2. Usage of addChild
//set the children elt11.addChild(elt21); elt12.addChild(elt22); root.addChild(elt11); root.addChild(elt12);
A given node can be removed from the tree by calling the detach()
method. A node can also be removed from the tree by calling the remove
method of the returned iterator which will also call the detach method of
the particular node internally.
Creating an object model from an existing document involves a second concept, namely
that of a builder. The responsibility of the builder is to
instantiate nodes corresponding to the information items in the document being parsed.
Note that as for programmatically created object models, this still involves the
factory, but it is now the builder that will call the createXxx
methods of the factory.
There are different types of builders, corresponding to different types of
input documents, namely: plain XML, SOAP, XOP and MTOM. The appropriate type of
builder should be created using the corresponding static method in
OMXMLBuilderFactory. Example 2.3, “Creating an object model from an input stream” shows the
correct method of creating an object model for a plain XML document from an input stream.
![[Note]](images/note.png) | |
As explained in ???, this is the recommended way
of creating a builder starting with Axiom 1.2.11. In previous versions, this was done
by instantiating |
Example 2.3. Creating an object model from an input stream
//create the input stream InputStream in = new FileInputStream(file); //create the builder OMXMLParserWrapper builder = OMXMLBuilderFactory.createOMBuilder(in); //get the root element OMElement documentElement = builder.getDocumentElement();
Several differences exist between
a programmatically created OMNode and OMNode instances created by a builder. The most
important difference is that the former will have no builder object enclosed,
where as the latter always carries a reference to its builder.
As stated earlier, since the object model is built as and
when required, each and every OMNode should have a reference to its builder.
If this information is not available, it is due to the object being created
without a builder. This difference becomes evident when the user tries to get
a non caching pull parser from the OMElement. This will be discussed in more
detail in Chapter 3, Advanced Operations with Axiom.
In order to understand the requirement of the builder reference in each
and every OMNode, consider the following scenario. Assume that the parent
element is built but the children elements are not. If the parent is asked to
iterate through its children, this information is not readily available to
the parent element and it should build its children first before attempting
to iterate them. In order to provide a reference of the builder, each and
every node of the object model should carry the reference to its builder. Each
and every OMNode carries a flag that states its build status. Apart from this
restriction there are no other constraints that keep the programmer away from
mixing up programmatically made OMNode objects with OMNode objects built from
builders.
The SOAP object hierarchy is made in the most natural way for a
programmer. An inspection of the API will show that it is quite close to the
SAAJ API but with no bindings to DOM or any other model. The SOAP classes
extend basic Axiom classes (such as the OMElement) hence, one can access a SOAP
document either with the abstraction of SOAP or drill down to the underlying
XML Object model with a simple casting.
Namespaces are a tricky part of any XML object model and is the same in
Axiom. However, the interface to the namespace have been made very simple.
OMNamespace is the class that represents a namespace with intentionally
removed setter methods. This makes the OMNamespace immutable and allows
the underlying implementation to share the objects without any
difficulty.
Following are the important methods available in OMElement to handle
namespaces.
public OMNamespace declareNamespace(String uri, String prefix); public OMNamespace declareNamespace(OMNamespace namespace); public OMNamespace findNamespace(String uri, String prefix);
The declareNamespaceXX methods are fairly straightforward. Add a namespace
to namespace declarations section. Note that a namespace declaration that has
already being added will not be added twice. findNamespace is a very handy
method to locate a namespace object higher up the object tree. It searches
for a matching namespace in its own declarations section and jumps to the
parent if it's not found. The search progresses up the tree until a matching
namespace is found or the root has been reached.
During the serialization a directly created namespace from the factory will only be added to the declarations when that prefix is encountered by the serializer. More of the serialization matters will be discussed in the section called “Serializer”.
The following simple code segment shows how the namespaces are dealt in OM
Example 2.4. Creating an OM document with namespaces
OMFactory factory = OMAbstractFactory.getOMFactory();
OMNamespace ns1 = factory.createOMNamespace("bar","x");
OMElement root = factory.createOMElement("root",ns1);
OMNamespace ns2 = root.declareNamespace("bar1","y");
OMElement elt1 = factory.createOMElement("foo",ns1);
OMElement elt2 = factory.createOMElement("yuck",ns2);
OMText txt1 = factory.createOMText(elt2,"blah");
elt2.addChild(txt1);
elt1.addChild(elt2);
root.addChild(elt1);Serialization of the root element produces the following XML:
<x:root xmlns:x="bar" xmlns:y="bar1"><x:foo><y:yuck>blah</y:yuck></x:foo></x:root>
Traversing the object structure can be done in the usual way by using the
list of children. Note however, that the child nodes are returned as an
iterator. The Iterator supports the 'Axiom way' of accessing elements and is
more convenient than a list for sequential access. The following code sample
shows how the children can be accessed. The children are of the type OMNode
that can either be OMText or OMElement.
Iterator children = root.getChildren();
while(children.hasNext()){
OMNode node = (OMNode)children.next();
}
Apart from this, every OMNode has links to its siblings. If more thorough
navigation is needed the getNextOMSibling()
and getPreviousOMSibling() methods can be
used. A more selective set can be chosen by using the
getChildrenWithName(QName) methods.
The getChildWithName(Qname) method
returns the first child that matches the given QName and
getChildrenWithName(QName) returns a collection containing all the matching
children. The advantage of these iterators is that they won't build the whole
object structure at once, until its required.
![[Important]](images/important.png) | |
As explained in ???, in Axiom 1.2.10 and earlier, all iterator implementations internally stayed one step ahead of their apparent location. This could have the side effect of building elements that are not intended to be built at all. |
An Axiom tree can be serialized either as the pure object model or the pull event
stream. The serialization uses a XMLStreamWriter object to write out the
output and hence, the same serialization mechanism can be used to write
different types of outputs (such as text, binary, etc.).
A caching flag is provided by Axiom to control the building of the in-memory
object model. The OMNode has two methods,
serializeAndConsume and serialize. When
serializeAndConsume is called the cache flag is reset and the serializer does
not cache the stream. Hence, the object model will not be built if the cache
flag is not set.
The serializer serializes namespaces in the following way:
When a namespace that is in the scope but not yet declared is encountered, it will then be declared.
When a namespace that is in scope and already declared is encountered, the existing declarations prefix is used.
When the namespaces are declared explicitly using the elements
declareNamespace()method, they will be serialized even if those namespaces are not used in that scope.
Because of this behavior, if a fragment of the XML is serialized, it will also be namespace qualified with the necessary namespace declarations.
Here is an example that shows how to write the output to the console, with reference to the earlier code sample- Example 2.3, “Creating an object model from an input stream” that created a SOAP envelope.
XMLStreamWriter writer =
XMLOutputFactory.newInstance().createXMLStreamWriter(System.out);
//dump the output to console with caching
envelope.serialize(writer);
writer.flush();or simply
System.out.println(root.toStringWithConsume());
The above mentioned features of the serializer forces a correct serialization even if only a part of the Axiom tree is serialized. The following serializations show how the serialization mechanism takes the trouble to accurately figure out the namespaces. The example is from Example 2.4, “Creating an OM document with namespaces” which creates a small object model programmatically. Serialization of the root element produces the following:
<x:root xmlns:x="bar" xmlns:y="bar1"><x:foo><y:yuck>blah</y:yuck></x:foo></x:root>
However, serialization of only the foo element produces the following:
<x:foo xmlns:x="bar"><y:yuck xmlns:y="bar1">blah</y:yuck></x:foo>
Note how the serializer puts the relevant namespace declarations in place.
The following code segment shows how to use Axiom for completely building a document and then serializing it into text pushing the output to the console. Only the important sections are shown here. The complete program listing can be found in Chapter 6, Appendix.
//create the input stream InputStream in = new FileInputStream(file); //create the builder OMXMLParserWrapper builder = OMXMLBuilderFactory.createOMBuilder(in); //get the root element OMElement documentElement = builder.getDocumentElement(); //dump the out put to console with caching System.out.println(documentElement.toStringWithConsume());
The normal way to create XMLStreamReader and
XMLStreamWriter instances is to first request a
XMLInputFactory or XMLOutputFactory
instance from the StAX API and then use the factory methods to create the
reader or writer.
Doing this every time a reader or writer is created is cumbersome and also
introduces some overhead because on every invocation the newInstance
methods in XMLInputFactory and XMLOutputFactory
go through the process of looking up the StAX implementation to use and creating
a new instance of the factory. The only case where this is really needed is when
it is necessary to configure the factory in a special way (by setting properties on it).
Axiom has a utility class called StAXUtils that provides
methods to easily create readers and writers configured with default settings.
It also keeps the created factories in a cache to improve performance. The caching
occurs by (context) class loader and it is therefore safe to use StAXUtils
in a runtime environment with a complex class loader hierarchy.
![[Caution]](images/caution.png) | |
Axiom 1.2.8 implicitly assumed that |
StAXUtils also enables a property file based configuration
mechanism to change the default factory settings at assembly or deployment time of
the application using Axiom. This is described in more details in
the section called “Changing the default StAX factory settings”.
| |
The |
The methods in StAXUtils to create readers and writers
are rather self-explaining. For example to create an XMLStreamReader
from an InputStream, use the following code:
InputStream in = ... XMLStreamReader reader = StAXUtils.createXMLStreamReader(in);
As we have seen previously, when creating an object model from a stream, all nodes keep a
reference to the builder and thus to the underlying parser. Since an XML parser instance is
a heavyweight object, it is important to release it as soon as it is no longer required.
The close method defined by the OMSerializable
interface it used for that. Note that it doesn't matter an which node this method is
called; it will always close and release the parser for the whole tree. The
build parameter of the close method specifies
if the node should be built before closing the parser.
To illustrate this, consider Example 2.3, “Creating an object model from an input stream”. After finishing the processing of the object model and assuming that it will not access the object model afterwards, the code should be completed by the following instruction:
documentElement.close(false);
Closing the parser is especially important in applications that process large numbers of XML documents. In addition, some StAX implementation are able to “recycle” parsers, i.e. to reset a parser instance and to reuse it on another input stream. However, this can only work if the parser has been closed explicitly or if the instance has been marked for finalization by the Java VM. Closing the parser explicitly as shown above will reduce the memory footprint of the application if this type of parser is used.
The fact that Axiom uses deferred building means that a call to a method in one
of the object model classes may cause Axiom to read events from the underlying
StAX parser, unless the node has already been built or if it was created
programmatically. If an I/O error occurs or if the XML document being read is
not well formed, an exception will be reported by the parser. This exception is
propagated to the user code as an OMException.
Note that OMException is an unchecked exception.
Strictly speaking this is in violation of the principle that unchecked exceptions
should be reserved for problems resulting from programming problems.
There are however several compelling reasons to use unchecked exceptions in this
case:
The same API is used to work with programmatically created object models and with object models created from an XML document. On a programmatically created object model, an
OMExceptionin general indicates a programming problem. Moreover one of the design goals of Axiom is to give the user code the illusion that it is interacting with a complete in-memory representation of an XML document, even if behind the scenes Axiom will only create the objects on demand. Using checked exceptions would break that abstraction.In most cases, code interacting with the object model will not be able to recover from an
OMException. Consider for example a utility method that receives anOMElementas input and that is supposed to extract some data from this information item. When a parsing error occurs while iterating over the children of that element, there is nothing the utility method could do to recover from this error.The only place where it makes sense to catch this type of exception and to attempt to recover from it is in the code that creates the
XMLStreamReaderand builder. It is clear that it would not be reasonable to force developers to declare a checked exception on every method that interacts with an Axiom object model only to allow propagation of that exception to the code that initially created the parser.
The situation is actually quite similar to that encountered in three-tier applications, where the DAO layer in general wraps checked exceptions from the database in an unchecked exception because the business logic and the presentation tier will not be able to recover from these errors.
When catching an OMException special attention should
be paid if the code handling the exception again tries to access the object model.
Indeed this will inevitably result in another exception being triggered, unless the
code only accesses those parts of the tree that have been built successfully.
E.g. the following code will give unexpected results because the call to
serializeAndConsume will almost certainly trigger another
exception:
OMElement element = ...
try {
...
} catch (OMException ex) {
ex.printStackTrace();
element.serializeAndConsume(System.out);
} | |
In Axiom versions prior to 1.2.8, an attempt to access the object model after
an exception has been reported by the underlying parser may result in an
|
| |
The discussion in this section suggests that Axiom should make a
clear distinction between exceptions caused by parser errors and
exceptions caused by programming problems or other errors, e.g.
by using distinct subclasses of |